
Machine Learning: Bayesian Inference
Used in Computational Vision calculations, Bayesian Inference is a method to update model hypotheses z following observations on data x.
It utilizes Bayes’ theorem, that -
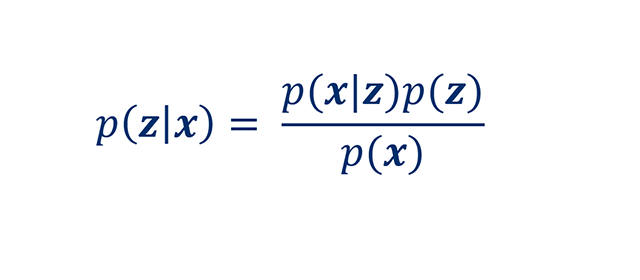
The prior hypothesis on the latent variables z, p(z), quantifies our belief before a new batch of data x is observed. We assume that data x are generated from a constant data-generating process, p(x) and that we can quantify the likelihood of observing x given our hypothesis z through the conditional distribution p(x|z). Despite being a somewhat abstract concept, Bayesian Inference has many real-world applications and is a powerful tool that underpins many machine learning techniques. A non-exhaustive list of applications includes:
- Probabilistic and generative modelling – for example image standardization and Variational AutoEncoders
- Uncertainty quantification for parametric models – for example Bayesian neural networks
One of the most ubiquitous applications for Bayesian Inference is uncertainty quantification. In parametric regression for example, our observed data are in fact pairs of datum (x,y) and our task is to predict labels y on new data points x, given that we have a closed-form expression for the posterior distribution p(z|{x,y}). Note that in this setting, the likelihood has a fixed-form of p(y|x,z). Uncertainty is then quantified by the posterior predictive distribution,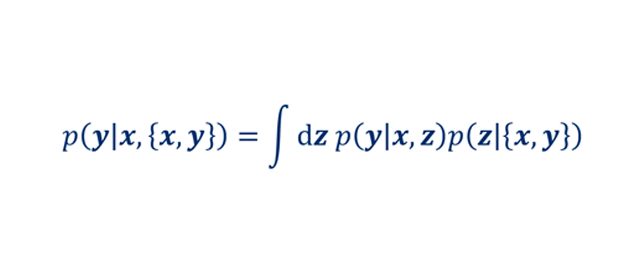
which has a closed-form expression for a limited number of scenarios, for example when p(y|x,z) is a normal distribution with isotropic standard deviation and whose expected value is a linear model of z. Otherwise, samples of the latent variable z must be generated from the posterior distribution p(z|{x,y}) and the expected value and variance of p(y│x,{x,y}) must be evaluated numerically.
It is worth concluding this introduction to Bayesian Inference by noting that the application of Bayes’ theorem as described here, assumes that we have a closed-form expression for evaluating the posterior distribution p(z│x). This is not always the case and approximations of p(z│x) must often be made in order for model predictions to be used, for example via the posterior predictive distribution. A large branch of machine learning called approximate inference, in fact exists to achieve just this.
At Element, we use the Bayesian Inference method within our Digital Engineering operations. Contact our Digital Engineering team for more information.
Find related Resources
Digital Engineering Services

Modeling and Simulation
We specialize in modeling and simulation to accelerate your research and development initiatives, optimize your designs and support safe, efficient operations.

Digital Engineering Data Science and Machine Learning Services
Our Machine Learning and Data Science services offer customized solutions to transform your data into actionable insights.

Finite Element Analysis Services (FEA)
Element offers advanced numerical analysis service using Finite Element Analysis (FEA) techniques using industry standard software to predict the long term behavior of materials components and products when in service.

Discrete Element Method (DEM)
Our Discrete Element Method (DEM) services deliver innovative solutions that have helped companies across a wide range of industries.